
Who's the @RealQaiQai?
Natural Language processing is a Machine Learning application where we can train a computer to analyze and attempt to interpret human-readable text. Unfortunately, the underlying language of computers is math, so there needs to be a method to translate human-readable text into math. Word to Vector is a method to do just that. I have used Basilica to create Word2Vec embeddings of hundreds of tweets to solve one of the biggest social media mysteries of the last year….. WHO IS @REALQAIQAI?
In mid-August 2018, a new account for @RealQaiQai sent her first tweet. This alone doesn't seem odd as more than half a million users tweet daily. However, Qai Qai is a small African American baby doll who's the partner-in-crime to Olympia Ohanian, the daughter of Serena Williams and Alexis Ohanian. The @RealQaiQai has since become America's favorite doll with over 20k Twitter followers.
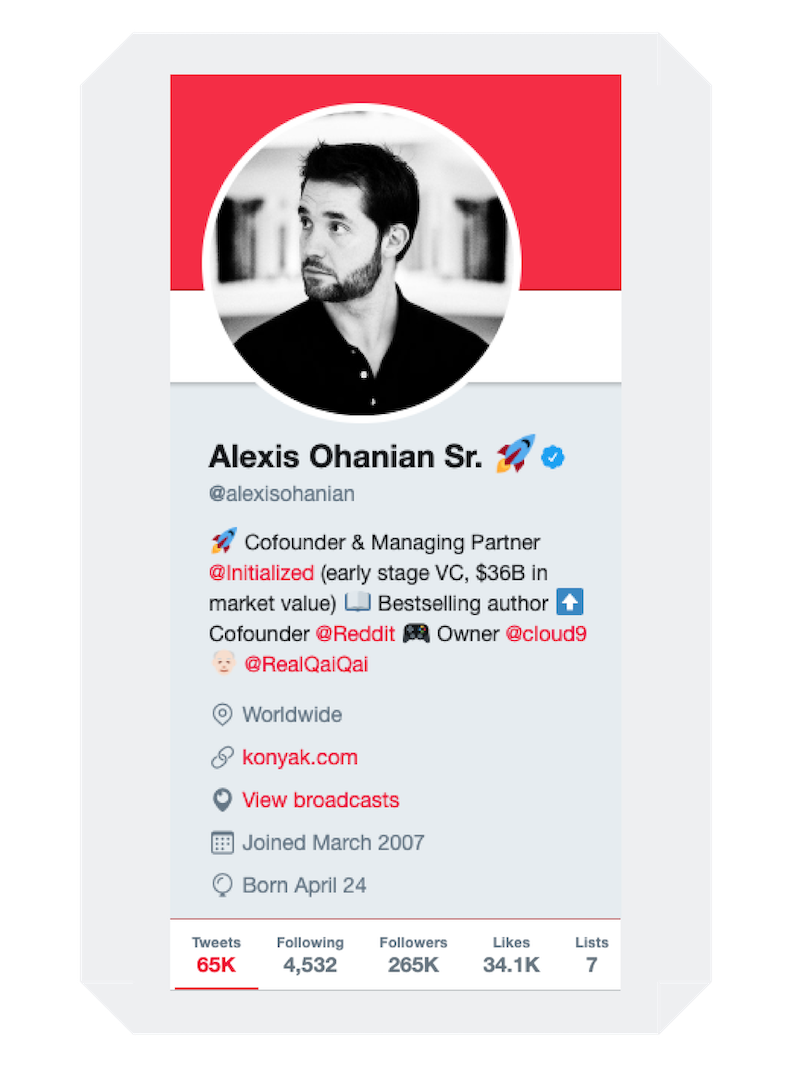
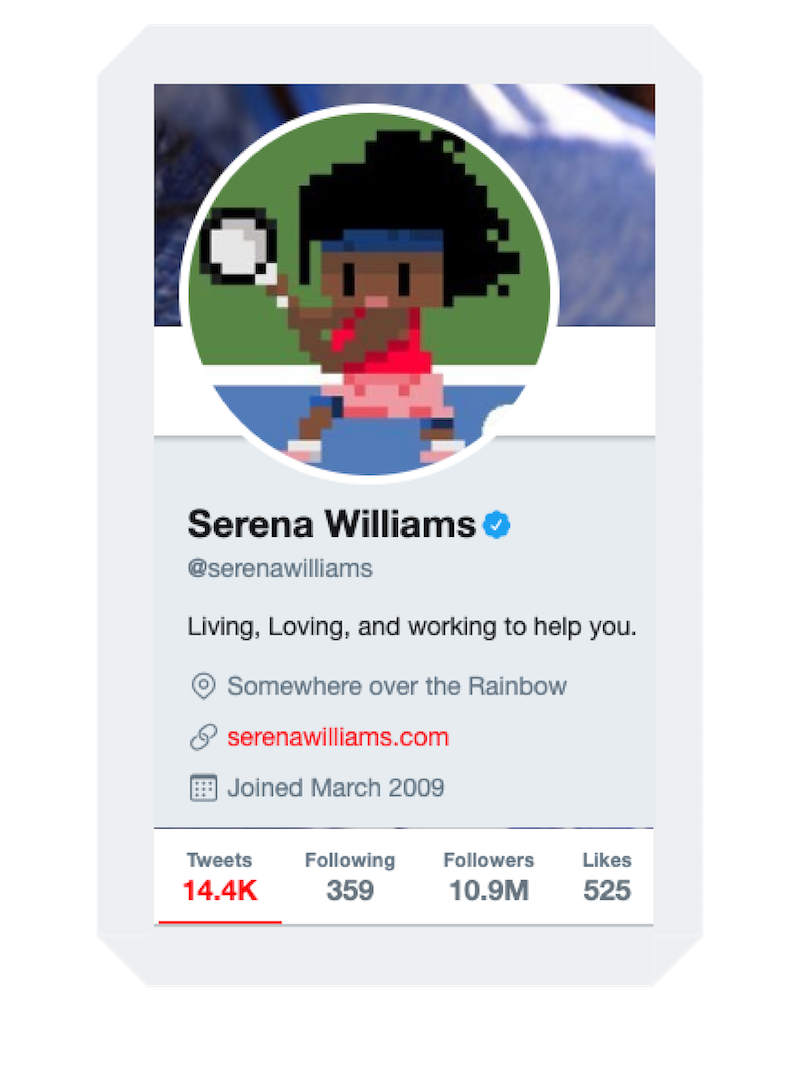
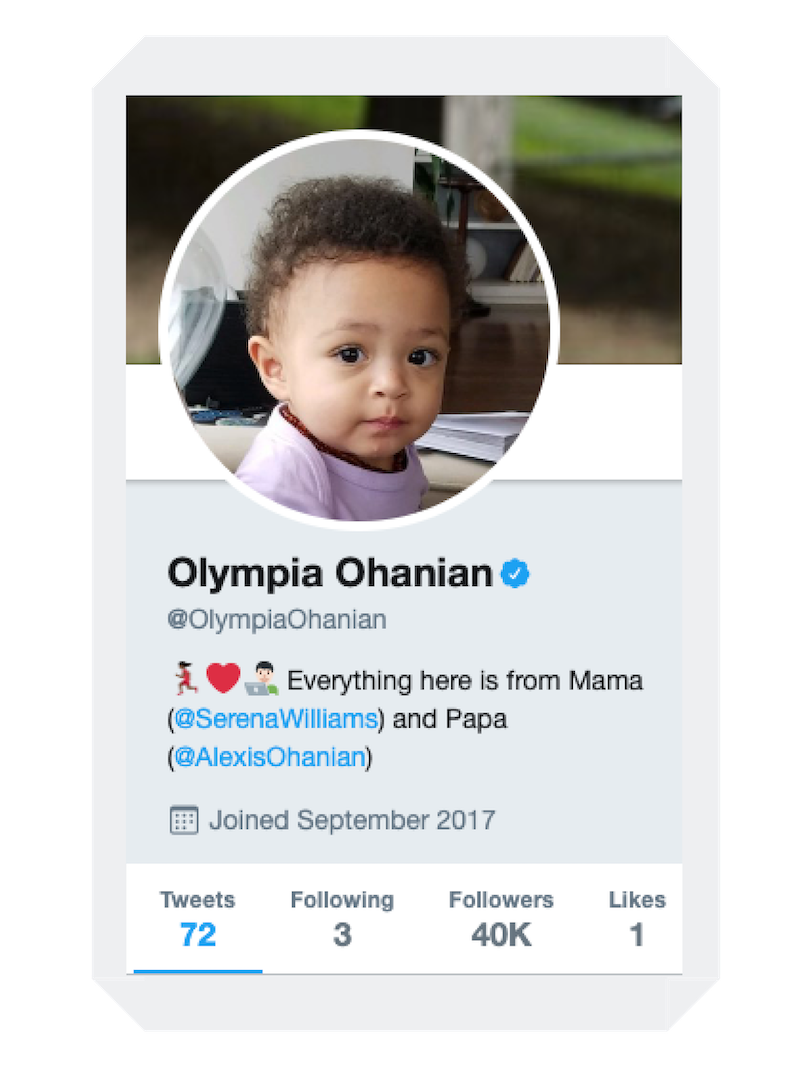
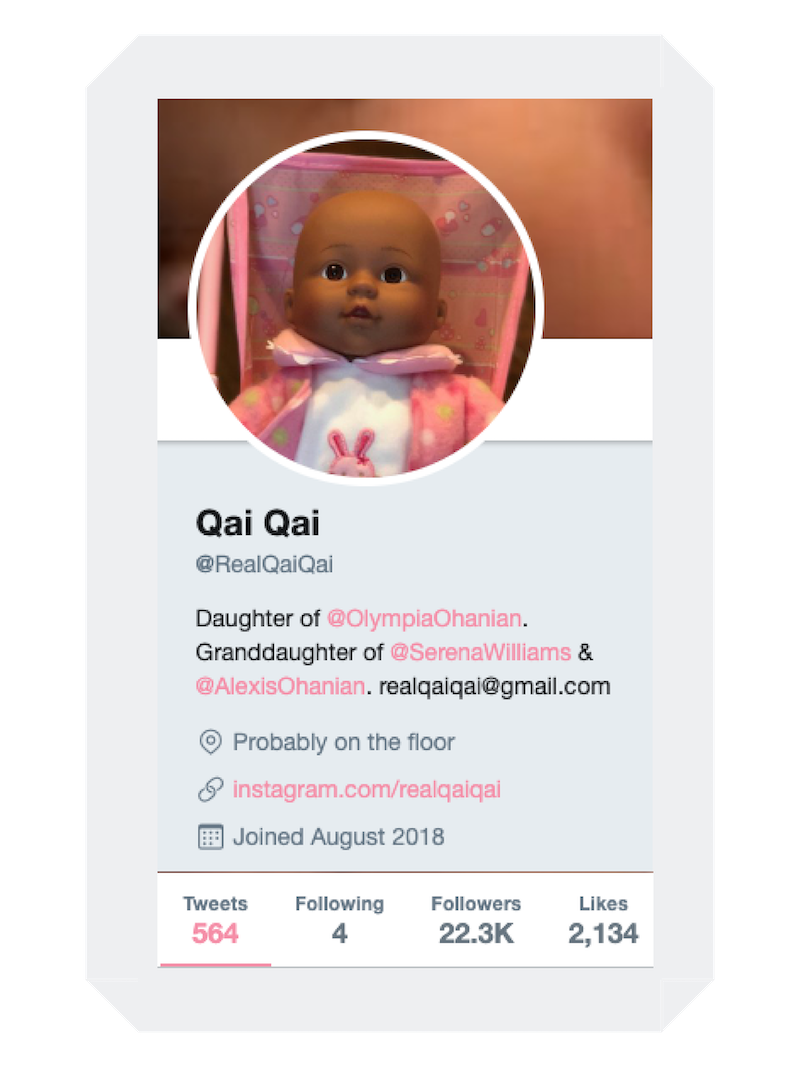
The world became obsessed with the blossoming relationship between Serena and Alexis in 2018, when the couple announced their engagement. In September, Olympia was born, and by August, the new parents were grandparents. Qai Qai the Doll became an instant hit on Twitter and Instagram with her catchy clap backs and beautiful pics from a doll's point of view. However, unlike Olympia's Twitter profile which clearly explains that both mom and dad manage the account, the adoring fans of @RealQaiQai have no idea which superstar parent is the author behind the account.
Many believe it's Alexis, the founder of Reddit, because of his background in tech and love of social media. Using Natural Language Processing and a Logistic Regression model, we can finally put this mystery to bed.
The Code
Using Twitter API
The first step to solving this 'who done it' is to pull tweet history from @alexisohanian, @serenawilliams, and @RealQaiQai. This was done through Twitter's developer API.
# User 1
username = "serenawilliams"
number_of_tweets=200
tweets = TWITTER.user_timeline(username, count=200, exclude_replies=True,
include_rts=False, tweet_mode='extended')
tmp=[]
tweets_for_csv = [tweet.full_text for tweet in tweets]
for j in tweets_for_csv:
tmp.append(j)Word to Vector with Basilica
Once we have all the tweets, we use Basilica to convert words to vectors. This process turns a word into a collection of numbers that can be understood by the computer. Once the words are vectors, the computer can analyze the speech patterns, word usage, and sentiment of the tweets.
user1 = []
for tweet in tweets:
user1_embedding = BASILICA.embed_sentence(tweet.full_text, model='twitter')
user1.append(user1_embedding)Apply Logistic Regression Model
We then feed all this analysis into a logistic regression model. We train the computer to identify which tweets were written by Serena and which were written by Alexis. After training, we fed the word to vector information from QaiQai. The logistic regression model can then predict which tweet was more similar to Serena's tweets, and which were more like Alexis.
import numpy as np
from sklearn.linear_model import LogisticRegression
embeddings = np.vstack([user1, user2])
labels = np.concatenate([np.ones(len(user1)),
np.zeros(len(user2))])
log_reg = LogisticRegression().fit(embeddings, labels)Predict Parent Author
And finally, we can compare the predictions of each tweet from @RealQaiQai to see which parent was predicted more often. Drum roll please…..
preds = []
for tweets in tmp3:
tweet_embedding = BASILICA.embed_sentence(tweets, model='twitter')
prediction = log_reg.predict(np.array(tweet_embedding).reshape(1, -1))
preds.append(prediction)Conclusion
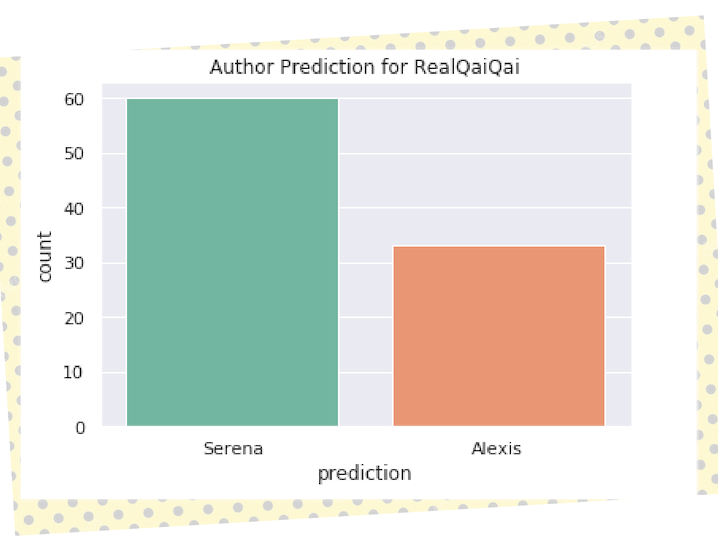
The parent behind @RealQaiQai is roughly twice as likely to be Serena than Alexis. The results don't definitively say that only Serena Williams is the author of @RealQaiQai, but it looks likely.
